
The recent slew of communal incidents and clashes across the country has led to an increase in the online conversation about it, with users sharing information around it in different regional languages.
Among the posts that have come up around these issues, a significant portion of them consist of misinformation and hateful speech that target minority communities using slang and derogatory language.
While a large share of this content – be it text, images or videos – makes direct claims to target communities, there has been a pattern of coded or camouflaged words that are used for the same purpose.
But they do not get taken down and continue to gain traction, despite containing language that may go against the platform’s policies. So, why does such content proliferate?
In this article, we will explore:
How the communally charged language presents a challenge to fact-checkers, moderators and automated tools.
Can these be overcome by collaborative efforts between humans and AI on social media platforms?
Slang, Slurs and the Human Challenges of Tracking Hateful Content
Despite a growing network of moderators and fact-checkers in India, the use of slangs, slurs and derogatory words tends to slip past their notice.
Sample this: A claim around a man’s murder in Delhi’s Naraina went viral on social media. The murder was given a false communal angle, and what we witnessed were the kind of words that were used in the posts. Users went on to blame the Muslim community for it and words such as ‘‘Izlam’,’Muzlims’ and ‘j!hadists’.
This poses a challenge for fact-checkers, moderators, and journalists who are monitoring large volumes of posts for inflammatory content on a daily basis. But experts believe that automated technology tools can be used for tracking such hateful language and posts.
Speaking to The Quint about the ability of technological tools, Tarunima Prabhakar, research lead at Tattle – a collective of technologists, researchers, journalists and artists who build tools to tackle misinformation – said that it was possible for tech tools which moderate social media platforms to track approximate matches of words.
"If you have a "slur list," which we've been crowd-sourcing, you should be able to do an approximate match and see similar words. But there are limits in that. Someone was using a symbol instead of text to avoid and evade detection by platforms."Tarunima Prabhakar, research lead at Tattle
She added that while it would be "a bit of a cat-and-mouse chase", it is possible for platforms to detect and flag word variations to moderators in posts published by its users.
When Words Turn Communal, Context Is Key
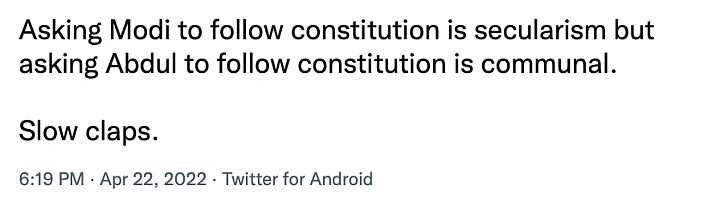
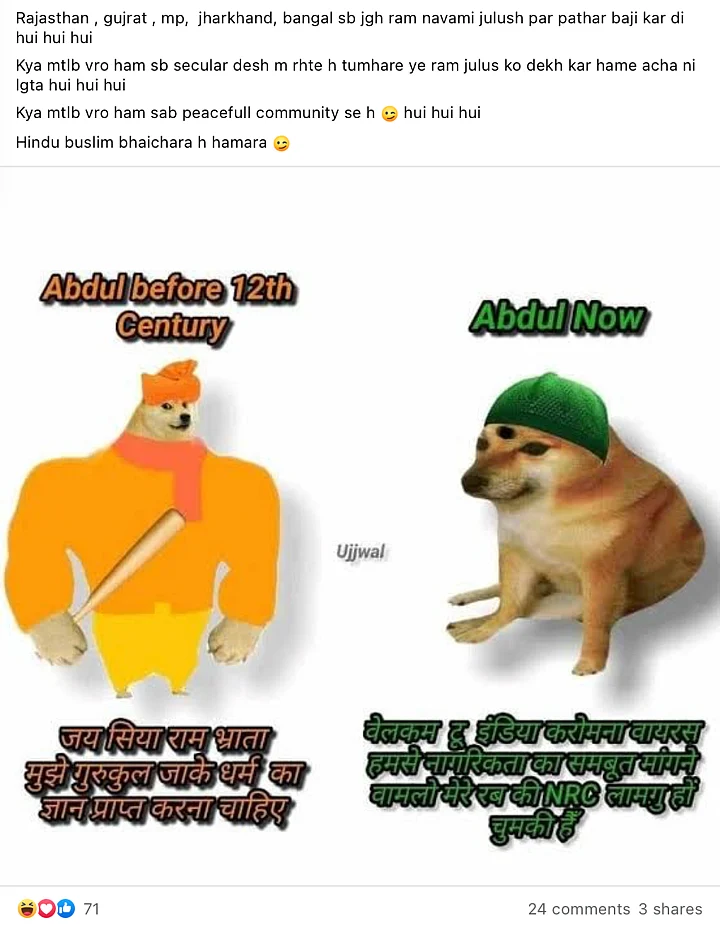
In many communal claims, we notice words which might not look offensive on the face of it, but are used to target communities. For instance: Instead of saying Muslims, users say 'Abdul', 'Peacefuls' to refer to the community.
(Note: Swipe right to view different use-cases of the name 'Abdul')

This post shows the use of the word 'Abdul'.
(Source: Twitter/Screenshot)



Now in this case, context would be required for both – human and technological moderation.
"To detect context, you would need someone to actually label context. You'll need instances of the data where it's been labelled as instances of content being problematic and not problematic," says Prabhakar adding that it was not easy as people might or might not agree on what is “problematic and what is not problematic”.
For instance, a developer who doesn't recognise that they "are not subject to abuse that most people are" and fail to realise that something that may not trigger them, might trigger others, is likely to code abusive content in a very different manner.
Another example of a context dependent post can be seen here, where a photograph from 2019 was recently shared in connection to the communal violence that broke out in Delhi's Jahangirpuri.
In another post, a picture of a man in a skullcap aiming a rock at a police person on the ground was shared with the text 'peacefuls', an oft-repeated sarcastic reference used in the context of the statement that Islam is a ‘religion of peace’.
According to the Internet Freedom Foundation’s (IFF) Apar Gupta, the problem with hateful language arises not only where innuendos or coded words are used often, but also in criticisms of “certain religious or caste-based practices which may, on a holistic level, input into a larger environment of violence against these groups.”
For instance the practice of Halal has been interpreted in various different ways and that has led to calls for economic boycott of Muslim-owned businesses.
How the Wide Range of Languages Poses a Challenge?
The problem with context and slang worsens when it comes to the range of languages in India. While the Center for Internet and Security (CIS) has annotators in different languages, they too face the same problems, because the connotation of a word, or a certain case of its usage, might not necessarily be problematic across different languages.
CIS' project to identify problematic language on social media started off with working on English-language datasets, based on which a set of guidelines were formed for future annotators to work on.
"We had a set of guidelines and then we have a bunch of annotators, six for each language and they were supposed to – from their own experience and with what our guidelines are saying – mark a post for it being problematic," a researcher working on the project told The Quint.
One problem that they faced was the casual usage of certain expletives or slurs in English, which when translated into Hindi, turned out to be problematic content that annotators felt should not be left up on social media.
While English-language annotators had the freedom and discretion to mark posts as problematic or unproblematic as per its specific use, the same did not apply to moderators in other languages like Hindi.
Similarly, transliterated language – Hindi words written in English text – such as the word 'शांतिदूत' (peace messenger) being written as 'shantidoot' tends to escape tools that are built on datasets of specific languages.
This screenshot also refers to ‘Ola’ and ‘Uber’, which would generally refer to ride-hailing mobile apps in India, but are used by a section of social media users to refer to the phrase ‘Allahu Akbar,’ [Allah is the greatest], an Arabic expression used in different contexts by Urdu and Arabic speaking people around the world.
Additionally, a moderator working exclusively in English may not recognise this as potentially problematic content due to words having a neutral or positive connotation outside this context.
Remarking on the complexity of the issue due to “sheer volume of content alongside the multiplicity of ethnicities and languages,” Logically’s Ayushman Kaul told us that “algorithms themselves need to be updated and refined frequently to keep track of changes in extremist or communal movements in the country.”
Then What’s the Way Forward?
The immediate answer to the problem would be to change the way the automated systems are modelled, and for platforms to employ more people who speak a variety of languages for moderation.
CIS' approach is not devoid of its problems. "But even this step is not being taken by big tech," said the researcher.
“I would say that the problem that has been discovered is that Silicon Valley companies haven’t done what they can do in clear instances of hate speech, as revealed by investigations,” IFF’s Gupta noted.
In a response to The Quint, Meta said that the company has invested 16 million US dollars "to enhance safety and security." But a report published in The New York Times in 2021 revealed that the company’s spending in India – which is their largest market – is minuscule.
Despite having time, resource and manpower constraints, independent organisations have worked to highlight the desperate need for a multilingual system to be in place.
“Of course innuendos, hate cases and coded language is a problem because of context,” but Gupta suggests that platforms are not taking the “least necessary actions to disable organised networks” and more powerful entities that set a larger narrative which undermine communal harmony.
Kaul also emphasised on the requirement for a greater level of investment in human moderators who have nuanced understanding of socio-cultural contexts.
“There is no silver bullet solution,” wrote Kaul, saying that a collaborative effort, societal-level effort between social media platforms, host countries’ regulatory and judicial bodies, free and robust media and the civil society to make people “less vulnerable to such content as a whole.”
Most of the experts agree that while the platforms possess these resources, they use a 'one-for-all' approach for their content that simply doesn't work.
There exists a debate between having a scaled-up moderation approach (that is followed by social media platforms) and having very small, scaled down-approaches to tackle problems that reflect the smaller problems faced by different communities.
While these methods will gradually reduce the time between hateful language staying online and the content being taken down, Prabhakar states that there is no way to get ahead of the curve to proactively take this content down.
Placing the “ultimate responsibility” of maintaining communal harmony on the state itself, IFF’s Gupta elaborates that platforms, which have features to allow people to organise (to push content and create narratives) and behave in a coordinated manner, “can take steps and actions to create and mitigate” it.
A collaborative effort between users, moderators and a platform's team and resources is the ideal way forward in ensuring that social media, which may be with us for years to come, develops into a better space for all its users.